
Code Interpreter — Giving LLM Hands
Adding code execution to Large Language Model (LLM) applications
This is for anyone interested in building LLM applications.
As a brief, somewhat trivial intro, we should explain that LLMs at their core are pattern recognition & prediction systems — they predict the most probable next words (tokens) in a sequence. They don’t actually ‘understand’ or ‘execute’ anything — they predict text patterns. But, boy, do they thrive at it. For all the hype and mystery, LLMs are brute-forcing machines faking intelligence.
Given some input, they predict the best output… just text. If the input provides instructions on how to launch a tool, the LLM will construct output which we can use in our code to launch a tool (search the internet, open a document, etc.).
It will not exactly be an eye-opening statement if I say that code interpreter is one of the most important tools an LLM can have at its disposal. LLMs absolutely thrive at writing code. Give them the ability to also run the code they write, and magic starts to happen:
- create visualizations from data
- upload excel and have it changed, cleaned, transformed
- …create stuff out of thin air.
There are, of course, solutions you can just use off the shelf. Send the code to API and have it do the hard work. But this article is for anyone interested in building their own minimal code execution sandbox for python.
You can be pretty brutal about it, too. If you just want to build and run your own LLM app (whatever the use case is), you can simply let the LLM write the code and run it in exec().
But if we want to build an LLM app for more users, perhaps one deployed to the cloud, we face a crucial challenge: how to safely run arbitrary python code generated by the LLM while maintaining:
- your backend | execution environment isolation
- user isolation.
It is crucial to ensure that each execution is isolated to prevent interference with other user sessions and the main application.
The brief notes below explain how jupyter kernels can serve as independent ‘compute engines’ that execute code sent by an LLM agent.
Think of it as creating a secure sandbox where each user gets their own isolated python interpreter. When LLM decides it needs to generate and run some python code, that code is sent to a fresh kernel process that:
- runs completely separate from your main application
- has its own workspace and memory
- can be (should be) killed and cleaned up after use
- communicates back results via a standardized protocol
This ensures that even if LLM generates problematic code, it can’t crash your main application or interfere with other users. The kernel acts as a disposable compute unit — spin it up, run the code, capture the output, and shut it down cleanly.
Step 1: LLM Generates Code
- LLM outputs Python code as part of its response
- code needs to be extracted and sent to kernel for execution
Imagine the below example being part of your larger agent flow, where you are sending instructions together with user questions/requests to LLM and on API response, you are checking if it invoked a tool … if that tool is kernel you extract the code and send it to:
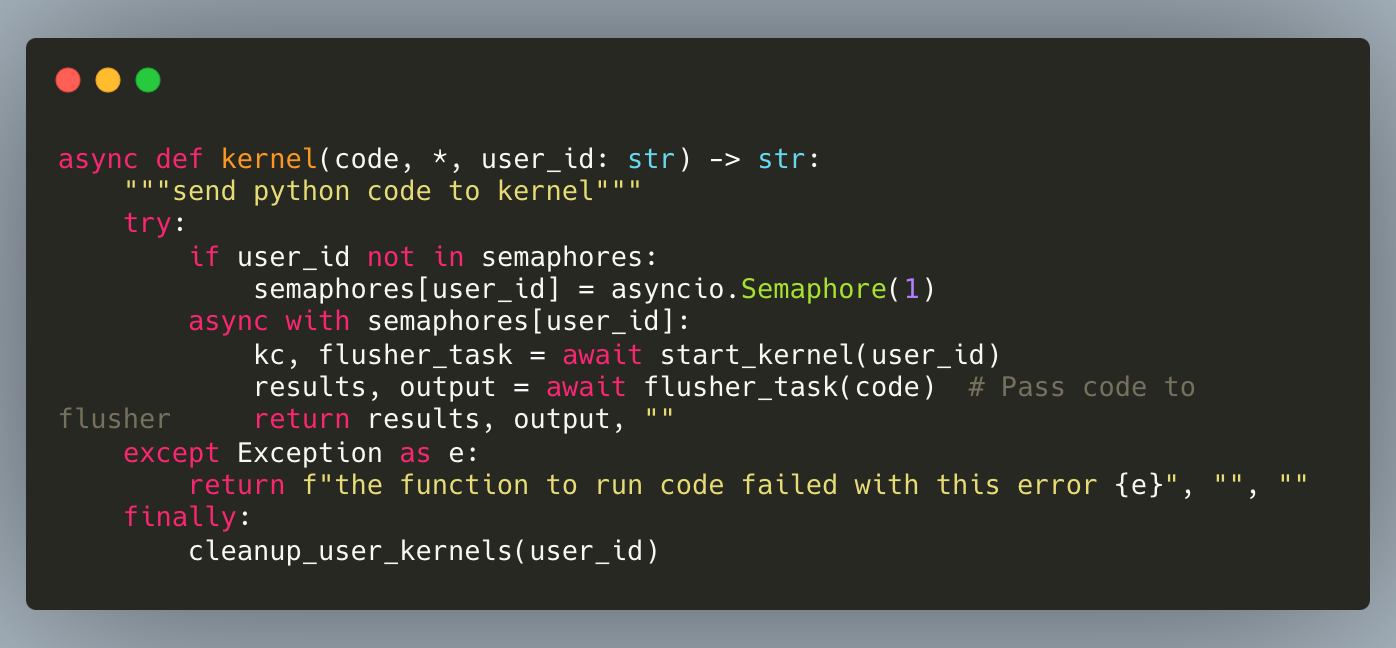
Step 2: Start Kernel Process
We use the subprocess module to start a new jupyter kernel as a separate process. Note that we set cwd to the user's workspace. Assuming you build an app for multiple users, you want that whatever is created in that sandbox gets saved for each user somewhere -> to her folder, right?
Note also we create Process ID — PID, which stores the kernel process ID for cleanup.
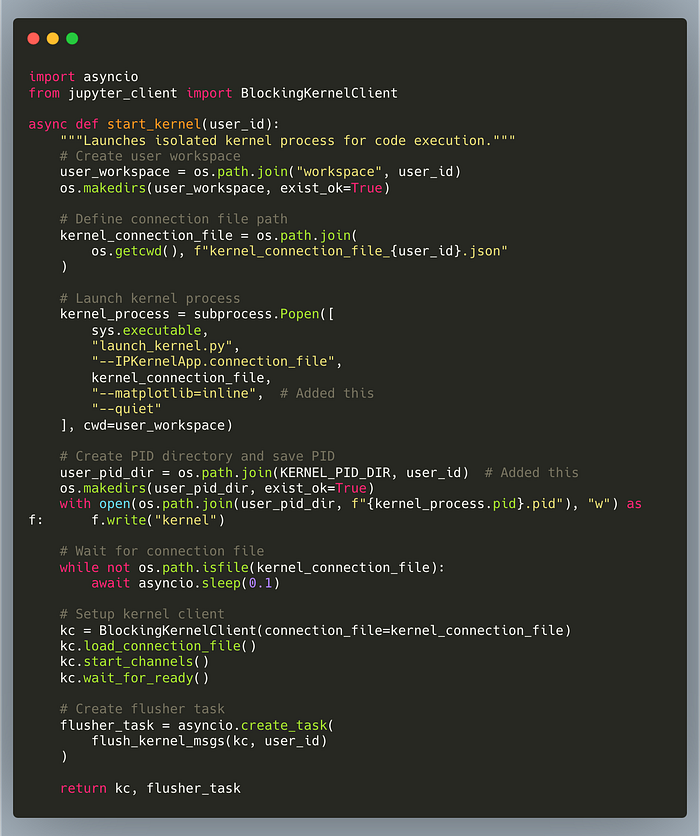
Step 3: Execute Code & Collect Output
Below we send the code to kernel execute (kc.execute) and we start receiving messages from kernel, which we collect to return and show back to LLM so that it knows if it achieved what it wanted.
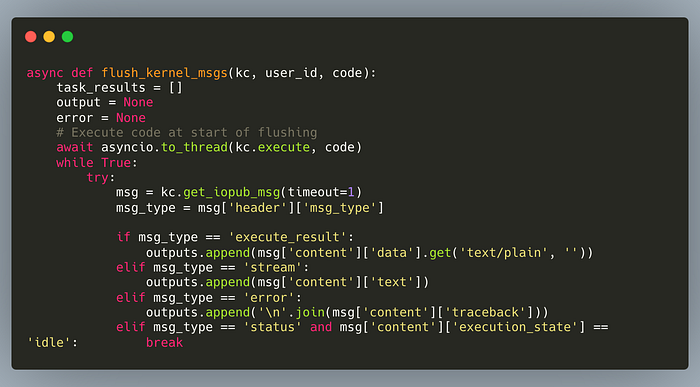
Step 4: Cleanup
After each code execution, I deliberately kill the kernel process using SIGKILL (the most forceful termination signal) to ensure complete cleanup. While this means starting a fresh kernel for each execution — impacting performance — it guarantees isolation and safety for my backend. This tradeoff prioritizes security over speed.
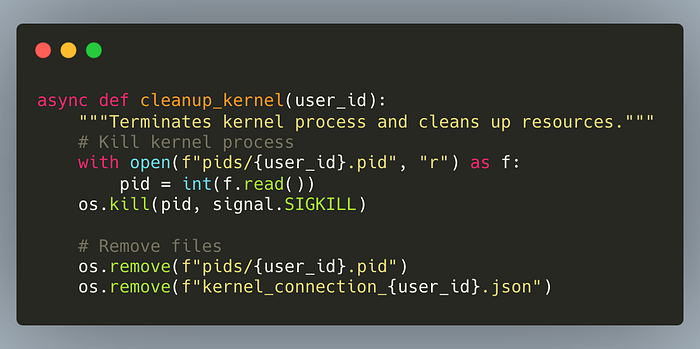
Additional detail (don’t need to know):
- Kernel Connection File — A JSON file containing network and security details required to communicate with a jupyter kernel. It allows your backend to know how to connect to the kernel process securely. In the code above it is created on startup (don’t worry about it).

2. Process IDs (PIDs) — Identifiers assigned by the operating system to each running process. They are used to track and manage individual kernel processes, and to terminate processes when they’re no longer needed. Each user, each execution gets its own PID. Prevents orphaned processes (bad!).
3. Communication Channels:
- Shell Channel: sends code to the kernel for execution.

- IOPub Channel: broadcasts kernel output.

4. Kernel Isolation — Each kernel runs as an independent process separate from the main application and other kernels.

5. BlockingKernel client — In our example above we used BlockingKernelClient from jupyter_client library because it is simple:
- synchronous API
- built-in message handling
- automatic channel management
...which is ideal for our use of one user, one execution at a time.
What could happen if you let LLM run arbitrary code in simple exec():
- malicious code could attempt to read or modify sensitive files on the server.
- infinite loops + consume excessive resources, leading to service degradation.
- code might scape the execution environment and affect the host system.
